大家好,我是云朵君!
导读: 今天给大家总结了一篇机器学习中的异常检测技术。通过理论结合实践的方法展开,我使用了两个数据集,根据数据集本身的特点,一个用以辅助展示异常检测模型工作特点,一个用以比较异常检测模型的实际应用效果。

👆点击关注|设为星标|干货速递👆
异常检测
数据集汇总的异常数据通常被认为是异常点、离群点或孤立点,特点是这些数据的特征与大多数数据不一致,呈现出"异常"的特点,检测这些数据的方法称为异常检测。
数据集出现异常值的常见原因
操作业务的影响
网站广告费用增加10倍,导致异常流量激增数据采集问题
数据缺失、不全、溢出、格式匹配等问题数据同步问题
异构数据库同步过程中丢失实验错误
数据提取或实验计划/执行错误数据处理错误
数据操作或数据集意外突变抽样错误
从错误或各种不同来源提取或混合数据自然存在
不是错误,而是数据多样性导致的数据新颖性
检测异常值对于几乎所有定量学科(即:物理、经济、金融、机器学习、网络安全)都非常重要。在机器学习和任何定量学科中,数据质量与预测或分类模型的质量一样重要。
异常检测方法
对正常和异常进行建模。这类似于监督分类,需要标记好数据。 在没有数据先验知识的情况下确定异常值。这类似于无监督聚类。 仅建模正常数据。这称为新奇性检测,类似于半监督识别。所谓新奇检测是识别新的或未知数据模式和规律的检测方法。
其实第三种新奇检测和异常检测是有关的,一开始的新奇点往往都是以一种离群点方式出现在数据中,这种离群方式一般会被认为是离群点,因此二者的检测和识别模式非常类似。但是经过一段时间之后,新奇数据一旦被证实为正常模式,那么新奇模式将被合并到正常模式之中,就不属于异常点的范畴。
本文将重点分别探讨前两种异常检测方法。

数据集说明
01 SECOM 数据集
SECOM(半导体制造)数据集,包括制造操作数据和半导体质量数据。它包含了从晶圆制造生产线上获得的1567项观察结果。每个观测值是590个传感器测量值加上一个合格/不合格测试的标签。
该数据集是带有标签的数据集,用于有监督分类异常检测技术。
02 Pokemon 数据集
该数据集开源于Kaggle Pokemon[1],其包括 721 只神奇宝贝,包括它们的编号、名称、第一和第二类型以及基本数据:生命值、攻击、防御、特攻、特防和速度。
本文只选择其中两列["HP", "speed"]在散点图中观察结果,之所以只选择两列,是因为二维有利于可视化。而本文的这些方法可以按多个维度进行扩展。
HP:生命值或生命值,定义了神奇宝贝在晕倒前可以承受多少伤害 speed:决定每轮哪个神奇宝贝首先攻击
不能仅通过攻击和防御来推断神奇宝贝的类型。可以在 2D 空间中绘制两个变量,并用作机器学习的示例。
该数据集是选择其中两列或某几列,则是带无标签的数据集,用于无监督聚类异常检测技术[2]。
异常检测算法
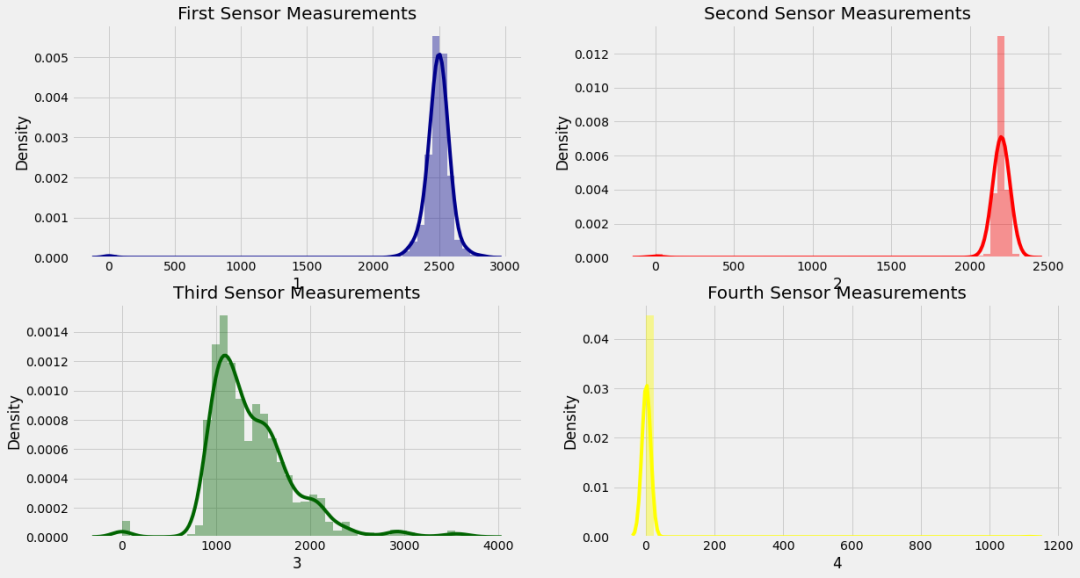
因半导体制造数据集数据较多,且存在缺失值,因此首先对进行初步的探索。
看前四列的分布
sns.distplot(data['1'], color = 'darkblue')
标签饼图
size = data['Pass/Fail'].value_counts()
plt.pie(size, labels =['Fail', 'Pass'],
colors = ['orange', 'green'], explode = [0, 0.1],
autopct = "%.2f%%", shadow = True)
热图看相关性
sns.heatmap(data.corr(), cmap = 'copper')
数据集采样方法
异常检测数据一般均为非常不平衡数据集,下面这两篇有详细介绍不平衡数据集的处理方法。
一个企业级数据挖掘实战项目|教育数据挖掘
机器学习中样本不平衡,怎么办?
这里分别采用欠采样和过采样两种方法来处理数据集。数据集采样后,选用XGBoost分类器作为检测算法,比较两种采样后的效果。
为比较采样后的效果,首先用XGBoost训练并预测未采用采样方法的数据集,并运用混淆矩阵评估模型效果。
# 划分训练集和测试集合
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(
x, y, test_size = 0.2, random_state = 0)
# 数据标准化
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
x_train = sc.fit_transform(x_train)
x_test = sc.transform(x_test)
# 模型训练
from xgboost.sklearn import XGBClassifier
model = XGBClassifier(eval_metric='logloss')
model.fit(x_train, y_train)
y_pred = model.predict(x_test)
# 模型评价
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
plt.rcParams['figure.figsize'] = (8, 6)
sns.set(style = 'dark', font_scale = 1.4)
sns.heatmap(cm, annot = True, annot_kws = {"size": 15})
由结果可看出,XGBoost未将未进行采样的数据中的异常数据检测出来。
数据集欠采样
欠采样方法在教育数据挖掘案例中有详细介绍,此处就不展开介绍。直接选用NearMiss下采样方法:
from imblearn.under_sampling import NearMiss
under_sample = NearMiss(version=1)
X_resampled, y_resampled = under_sample.fit_resample(X, y)
# 同样适用XGBClassifier
model = XGBClassifier(eval_metric='logloss')
运用混淆矩阵评价欠采样后的模型效果。
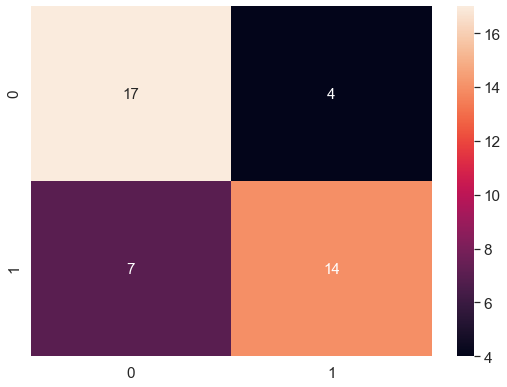
数据集欠采样 在 21个缺陷半导体中成功检测出14个,这是很厉害的。如果我们有更多的数据来训练模型,该方法效果将会更好。
网格搜索调参
采样是从数据集端来提升最终模型效果,而这里使用的模型是默认参数,因此还可以调节模型参数,使得模型效果达到最佳状态。这里选用网格搜索来选择最佳模型,这种方法简单粗暴,缺点是当参数过多或交叉验证折数过多,将会非常耗时。
为了方便演示,这里搜索的参数只设定一个最大深度"max_depth",及折数为2,在实际应用中,可以根据实际情况选择使用合适的参数。
# 应用网格搜索CV,找出具有最优参数的最优模型
from sklearn.model_selection import GridSearchCV
parameters = [{'max_depth' : [1, 2, 3, 4, 5, 6]}]
grid_search = GridSearchCV(estimator = model,
param_grid = parameters,
scoring = 'accuracy',
cv = 2, n_jobs = -1)
grid_search = grid_search.fit(x_train_us, y_train_us)
best_accuracy = grid_search.best_score_
best_parameters = grid_search.best_params_
根据网格搜索得到的最佳参数来调整模型参数,以到达最佳异常检测模型。
当然,XGBoost模型本身也有自带处理不平衡样本数据集的参数"scale_pos_weights",可以是如下设置。
weights = (y == 0).sum()/(1.0*(y == -1).sum())
scale_pos_weights = weights,
调整后的模型 在21个缺陷半导体中成功检测出17个。
XGBoost输出特征重要性
如果数据集维度过高,也有可能会影响异常检测结果。无用的特征将会干扰模型检测异常点。运用XGBoost的特种重要性方法xgb.feature_importances_ 得到特征重要性,也可以运用xgb.plot_importance直接绘制特征重要性图直观观察哪些特征最重要。
选择重要特征,以此来修正模型,本文将不做过多探讨,大家可以尝试。
import xgboost as xgb
xgb.plot_importance(model, height = 1, color = colors, grid = True,
importance_type = 'cover', show_values = False)
数据集过采样
在一个典型的分类问题中(使用一个分类算法对一组图像进行分类,给定一组带标签的图像训练集),有许多方法可以用于对数据集进行过采样。最常见的技术被称为SMOTE。
from imblearn.over_sampling import SMOTE
x_resample, y_resample = SMOTE().fit_resample(x, y.values.ravel())
经过过采样,划分训练集和测试集、数据标准化、网格搜索调参及混淆矩阵的绘制,得到如下结果
数据集过采样 在21个检测件中成功检测出17个,从精度上来说很不错。如果数据集的大小再大一点,那就更好了。
用于离群点检测的不同分类器
接下来比较几种用于离群点检测的分类器。
Isolation Forest Classifier孤立森林分类器
检测异常的最新技术之一为“孤立森林”。该算法基于这样一个事实,即异常是很少且不同的数据点。由于这些特性,这些异常很容易受到一种称为孤立的机制的影响。
这种方法从根本上不同于所有现有的方法。与常用的基本距离和密度测量方法相比,孤立是一种更有效和有效的检测异常的方法。此外,该算法具有较低的线性时间复杂度和较小的内存需求。无论数据集的大小如何,它都使用固定大小的小子样本,用少量的树构建一个性能良好的模型。
孤立森林基本原理
孤立森林,就像任何集成树方法一样,都是基于决策树构建的。在这些树中,首先通过随机选择一个特征,然后在所选特征的最小值和最大值之间选择一个随机分割值来创建分区。
为了在树中创建分支,孤立森林算法通过随机选择一个特征,然后在所选特征的最大值和最小值之间随机选择一个分割值来孤立观察结果。如果给定的观测值具有较低的此特征值,则选择的观测值将归左分支,否则归右分支。继续此过程,直到分割单个点或达到指定的最大深度为止。
逻辑上的论点是孤立异常观测更容易,因为只需要一些条件就可以将这些情况与正常观测分开。另一方面,孤立正常观测需要更多的条件。因此,一个异常得分可以计算为分离一个给定观测所需的条件的数量。
该算法构建分离的方法是首先创建孤立树,或随机决策树。然后计算得分作为路径长度以孤立观察。
孤立森林算法构建
用Pokemon数据集演示孤立森林算法
clf = IsolationForest(max_samples='auto',
random_state = 1,
contamination= 0.02)
preds = clf.fit_predict(X) # 参数y默认为None
data['isoletionForest_outliers'] = preds
data['isoletionForest_outliers'] = data['isoletionForest_outliers'].astype(str)
data['isoletionForest_scores'] = clf.decision_function(X)
孤立森林算法可视化
如下图所示,绘制出孤立森林的决策边界,正常点以及离群点。直观上看到这15个异常值似乎是合情合理的,并且他们不在主要的数据点团中。
孤立森林得分分布
孤立森林得分分布图是非常重要的,它有助于更好地识别特定情况下的正确的contamination 参数值。如果更改contamination 参数值,isoletionForest_scores将会随之更改,但分布将保持不变。算法会根据截断值调整分布图中的异常值。
sns.distplot(data['isoletionForest_scores'],
color='darkblue',label='if',
hist_kws = {"alpha": 0.5})
在SECOM数据集中应用
from sklearn.ensemble import IsolationForest
Fraud = data[data['Pass/Fail']==1]
Valid = data[data['Pass/Fail']==-1]
outlier_fraction = len(Fraud)/float(len(Valid))
model = IsolationForest(n_estimators=100,
max_samples=len(x_train),
contamination=outlier_fraction,
random_state=0, verbose=0)
model.fit(x_train, y_train)
scores_prediction = model.decision_function(x_train)
y_pred = model.predict(x_test)
孤立森林分类器 在13件产品中成功检测出11件缺陷产品,使召回准确率达到85%。如果数据更大一些,有更多缺陷的实例,那么这个算法会运行得更好。
Local Outlier Factor 局部离群因子
局部离群因子(LOF) 算法是一种无监督的离群点检测方法,它计算给定数据点相对于其邻近数据点的局部密度偏差,即点的 LOF 表示这个点的密度与其相邻点的密度之比。如果一个点的密度远小于其邻近点的密度(LOF ≫ 1),则该点远离密集区域,判为离群值。
邻居数小于附近的最大数量的对象可以局部离群值。在实践中,这样的信息通常是不可用的,通常情况下,使用n_neighbors=20其效果将会更好。
在Pokemon数据集中看下该算法的效果
clf = LocalOutlierFactor(n_neighbors=11)
y_pred = clf.fit_predict(X)
data['localOutlierFactor_outliers'] = y_pred.astype(str)
data['localOutlierFactor_scores'] = clf.negative_outlier_factor_
用如下图所示,一个比较有意思的散点图,数值点被大小不同的圈圈围住,该圈圈根据离群因子得分大小来定义,不同颜色表示是否是离群点。这样就能够较为直观地观察出该算法所判断出的离群值(红色圈)。
在SECOM数据集中应用
from sklearn.neighbors import LocalOutlierFactor
model = LocalOutlierFactor(n_neighbors=20, algorithm='auto',
leaf_size=30, metric='minkowski',
p=2, metric_params=None,
contamination=outlier_fraction)
model.fit(x_train, y_train)
y_pred = model.fit_predict(x_test)
局部离群因子分类器 在13件产品中成功检测出11件缺陷产品,使召回准确率达到85%。如果数据更大一些,有更多缺陷的实例,那么这个算法会运行得更好。
One Class SVM 单分类支持向量机
在单分类支持向量机中,支持向量模型在只有一个类的数据上进行训练,即“正常”类。它可以推断一般情况下的性质,并从这些性质可以预测哪些例子不像一般情况下的例子。这对于异常检测很有用,因为缺少训练示例是异常的定义:也就是说,通常很少有网络入侵、欺诈或其他异常行为的例子。
在Pokemon数据集中看下该算法的效果
clf = svm.OneClassSVM(nu=0.07,kernel='rbf',gamma='auto')
outliers = clf.fit_predict(X)
data['ocsvm_outliers'] = outliers
data['ocsvm_outliers'] = data['ocsvm_outliers'].apply(lambda x: str(-1) if x==-1 else str(1))
data['ocsvm_scores'] = clf.score_samples(X)
print(data['ocsvm_outliers'].value_counts())
从上图中可以较为直观地看出,单分类支持向量机异常检测效果并不是很理想,下面看看在半导体数据集中的应用效果如何。
在SECOM数据集中应用
from sklearn.svm import OneClassSVM
model = OneClassSVM(kernel ='rbf', degree=3,
gamma=0.1,nu=0.005,
max_iter=-1)
model.fit(x_train, y_train)
y_pred = model.fit_predict(x_test)
单分类支持向量机 成功识别出13个缺陷项中的8个,同样这并不比隔离森林和局部因子离群算法好,因为它们都识别出了13个缺陷项中的11个。也许OneClassSVM在有更多缺陷项的情况下会工作得更好。
DBSCAN
最后再介绍一种无监督聚类离群检测算法,基于密度的聚类算法,其工作原理如下:
随机选择一个没有被分配给一个簇或被指定为离群值的点。通过观察epsilon距离内是否至少有min_samples个点来确定其是否是核心点。
将这个核心点和与其的距离 epsilon 内的所有点创建一个簇。
查找簇中每个点的 epsilon 距离内的所有点,并将它们添加到该簇中。查找所有新添加的点在 epsilon 距离内的所有点,并将它们添加到簇中。重复上述步骤。
在Pokemon数据集中看下该算法的效果
from sklearn.cluster import DBSCAN
outlier_detection = DBSCAN(eps = 20, metric='euclidean',
min_samples = 5, n_jobs = -1)
clusters = outlier_detection.fit_predict(X)
几种离群检测算法比较
Recall = np.array([80.9, 80.9, 84.6, 84.6, 61.5])
label = np.array(['UnderSampling', 'OverSampling',
'IsolationForest', 'LocalOutlier',
'OneClassSVM'])
indices = np.argsort(Recall)
color = plt.cm.rainbow(np.linspace(0, 2, 9))
plt.bar(range(len(indices)), Recall[indices], color = color)
附录
下面附录了两个绘图代码,感兴趣的小伙伴们可以参考。
绘制孤立森林决策边界
X_inliers = data.loc[data['isoletionForest_outliers']=='1'][[x1,x2]]
X_outliers = data.loc[data['isoletionForest_outliers']=='-1'][[x1,x2]]
xx, yy = np.meshgrid(np.linspace(X.iloc[:, 0].min()-5, X.iloc[:, 0].max()+10, 50),
np.linspace(X.iloc[:, 1].min()-5, X.iloc[:, 1].max()+10, 50))
Z = clf.decision_function(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
fig, ax = plt.subplots(figsize=(18, 8))
plt.title("Isolation Forest Outlier Detection with Outlier Areas", fontsize = 15, loc='center')
plt.contourf(xx, yy, Z, cmap=plt.cm.Pastel1)
inl = plt.scatter(X_inliers.iloc[:, 0], X_inliers.iloc[:, 1], c='white', s=30, edgecolor='k')
outl = plt.scatter(X_outliers.iloc[:, 0], X_outliers.iloc[:, 1], c='red',s=50, edgecolor='k')
plt.axis('tight')
plt.xlim((X.iloc[:, 0].min()-5, X.iloc[:, 0].max()+10))
plt.ylim((X.iloc[:, 1].min()-5, X.iloc[:, 1].max()+10))
plt.legend([inl, outl],["normal observations", "abnormal observations"],loc="upper left")
plt.show()
局部离群因子散点图绘制
fig, ax = plt.subplots(figsize=(23.5, 10))
ax.set_title('Local Outlier Factor Scores Outlier Detection', fontsize = 20,
loc='center', fontdict=dict(weight='bold'))
plt.scatter(X.iloc[:, 0], X.iloc[:, 1], color='k', s=3., label='Data points')
radius = ((data['localOutlierFactor_scores'].max() - data['localOutlierFactor_scores']
) / (data['localOutlierFactor_scores'].max() - data['localOutlierFactor_scores'].min())
).values
plt.scatter(X[l1].iloc[:, 0], X[l1].iloc[:, 1], s=2000 * radius[l1], edgecolors='darkblue',
facecolors='none',)
plt.scatter(X[l2].iloc[:, 0], X[l2].iloc[:, 1], s=2000 * radius[l2], edgecolors='red',
facecolors='none', label='Outlier scores')
plt.axis('tight')
legend = plt.legend(loc='upper right',fontsize=20)
legend.legendHandles[0]._sizes = [30]
legend.legendHandles[1]._sizes = [50]
plt.show();
参考资料
神奇宝贝数据集: https://www.kaggle.com/abcsds/pokemon
[2]异常检测技术: https://towardsdatascience.com/outlier-detection-theory-visualizations-and-code-a4fd39de540c

OK,今天的分享就到这里啦!
没看够?点赞在看走起来~后续更精彩~
云朵出品|必属精品

推荐阅读
2021-05-14

2021-07-05
2021-04-02
2020-10-18



发表评论 取消回复